Lately, I have been working on an ESP32 firmware using PlatformIO. I went with PlatformIO because it works quite nicely within my familiar Visual Studio Code environment. PlatformIO worked well for a few weeks until recently, when I started seeing the following errors.
WARNING: Ignoring invalid distribution -ycparser (/Users/thebitguru/.platformio/penv/lib/python3.10/site-packages) WARNING: Ignoring invalid distribution -uture (/Users/thebitguru/.platformio/penv/lib/python3.10/site-packages) WARNING: Ignoring invalid distribution -ryptography (/Users/thebitguru/.platformio/penv/lib/python3.10/site-packages) WARNING: Ignoring invalid distribution -configlib (/Users/thebitguru/.platformio/penv/lib/python3.10/site-packages) WARNING: Ignoring invalid distribution -ycparser (/Users/thebitguru/.platformio/penv/lib/python3.10/site-packages) WARNING: Ignoring invalid distribution -uture (/Users/thebitguru/.platformio/penv/lib/python3.10/site-packages) WARNING: Ignoring invalid distribution -ycparser (/Users/thebitguru/.platformio/penv/lib/python3.10/site-packages) ...
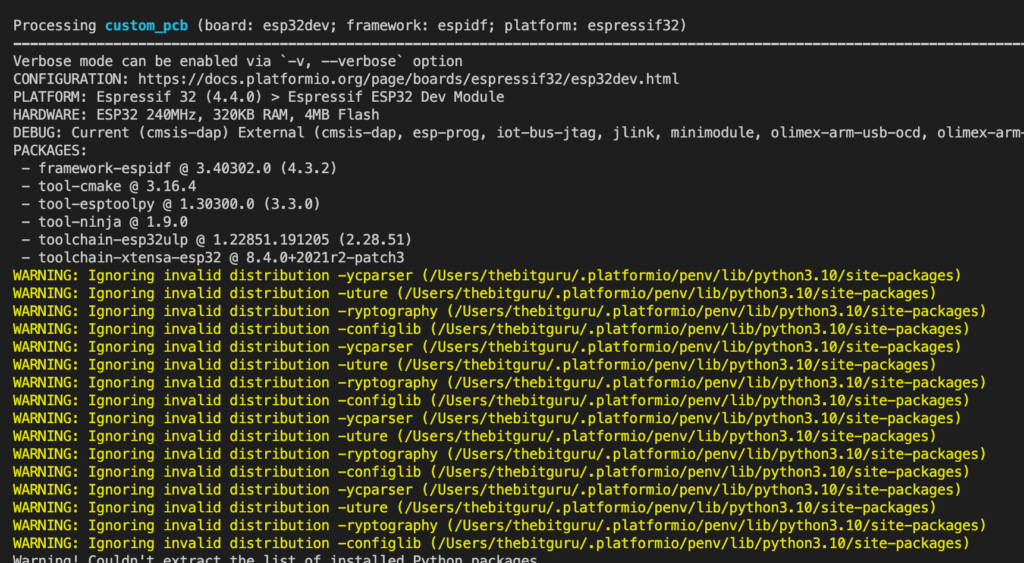
I haven’t touched Python in a while, so I wasn’t sure what was going on here. A quick Google search for these warnings with “PlatformIO” didn’t turn up anything. So, I had to dig deeper and search for general Python and PIP errors.
After a little searching, I found out that apparently pip leaves old package directories around if something goes wrong, and never cleans them up. These folders then result in these warnings. As suggested in the linked page, the solution was to delete all the directories starting with a tilde (~). Pip will then reinstall the missing packages as needed and the warnings will go away.
I can finally have a cleaner build output again! Now only if I can get the esp32_exception_decoder monitor filter to work again…